Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
Παρόμοιες με LessWrong (Curated & Popular)
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Every Friday and Sunday, Slate’s popular daily news podcast What Next brings you TBD, a clear-eyed look into the future. From fake news to fake meat, algorithms to augmented reality, Lizzie O’Leary is your guide to the tech industry and the world it’s creating for us to live in.
…
continue reading
Satguru Mata Sudiksha Ji Maharaj Discourses Podcast Channel
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Εφαρμογή podcast
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !

))
“The ‘strong’ feature hypothesis could be wrong” by lsgos
Manage episode 432958309 series 3364760
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
NB. I am on the Google Deepmind language model interpretability team. But the arguments/views in this post are my own, and shouldn't be read as a team position.
“It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout” : Elhage et. al, Toy Models of Superposition
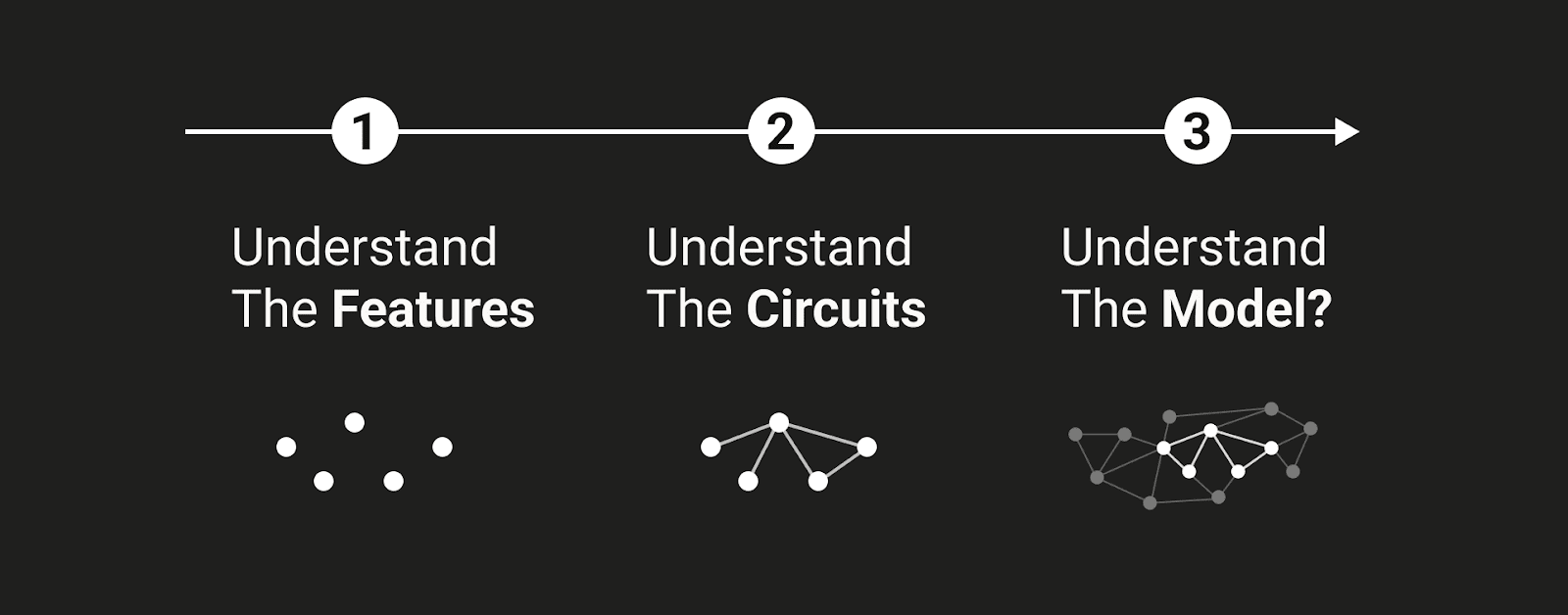
Recently, much attention in the field of mechanistic interpretability, which tries to explain the behavior of neural networks in terms of interactions between lower level components, has been focussed on extracting features from the representation space of a model. The predominant methodology for this has used variations on the sparse autoencoder, in a series of papers [...]
---
Outline:
(09:56) Monosemanticity
(19:22) Explicit vs Tacit Representations.
(26:27) Conclusions
The original text contained 12 footnotes which were omitted from this narration.
The original text contained 1 image which was described by AI.
---
First published:
August 2nd, 2024
Source:
https://www.lesswrong.com/posts/tojtPCCRpKLSHBdpn/the-strong-feature-hypothesis-could-be-wrong
---
Narrated by TYPE III AUDIO.
---
…
continue reading
“It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout” : Elhage et. al, Toy Models of Superposition
Recently, much attention in the field of mechanistic interpretability, which tries to explain the behavior of neural networks in terms of interactions between lower level components, has been focussed on extracting features from the representation space of a model. The predominant methodology for this has used variations on the sparse autoencoder, in a series of papers [...]
---
Outline:
(09:56) Monosemanticity
(19:22) Explicit vs Tacit Representations.
(26:27) Conclusions
The original text contained 12 footnotes which were omitted from this narration.
The original text contained 1 image which was described by AI.
---
First published:
August 2nd, 2024
Source:
https://www.lesswrong.com/posts/tojtPCCRpKLSHBdpn/the-strong-feature-hypothesis-could-be-wrong
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.359 επεισόδια
Manage episode 432958309 series 3364760
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
NB. I am on the Google Deepmind language model interpretability team. But the arguments/views in this post are my own, and shouldn't be read as a team position.
“It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout” : Elhage et. al, Toy Models of Superposition
Recently, much attention in the field of mechanistic interpretability, which tries to explain the behavior of neural networks in terms of interactions between lower level components, has been focussed on extracting features from the representation space of a model. The predominant methodology for this has used variations on the sparse autoencoder, in a series of papers [...]
---
Outline:
(09:56) Monosemanticity
(19:22) Explicit vs Tacit Representations.
(26:27) Conclusions
The original text contained 12 footnotes which were omitted from this narration.
The original text contained 1 image which was described by AI.
---
First published:
August 2nd, 2024
Source:
https://www.lesswrong.com/posts/tojtPCCRpKLSHBdpn/the-strong-feature-hypothesis-could-be-wrong
---
Narrated by TYPE III AUDIO.
---
…
continue reading
“It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a left-facing curve, or a dog snout” : Elhage et. al, Toy Models of Superposition
Recently, much attention in the field of mechanistic interpretability, which tries to explain the behavior of neural networks in terms of interactions between lower level components, has been focussed on extracting features from the representation space of a model. The predominant methodology for this has used variations on the sparse autoencoder, in a series of papers [...]
---
Outline:
(09:56) Monosemanticity
(19:22) Explicit vs Tacit Representations.
(26:27) Conclusions
The original text contained 12 footnotes which were omitted from this narration.
The original text contained 1 image which was described by AI.
---
First published:
August 2nd, 2024
Source:
https://www.lesswrong.com/posts/tojtPCCRpKLSHBdpn/the-strong-feature-hypothesis-could-be-wrong
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.359 επεισόδια
Alle Folgen
×Καλώς ήλθατε στο Player FM!
Το FM Player σαρώνει τον ιστό για podcasts υψηλής ποιότητας για να απολαύσετε αυτή τη στιγμή. Είναι η καλύτερη εφαρμογή podcast και λειτουργεί σε Android, iPhone και στον ιστό. Εγγραφή για συγχρονισμό συνδρομών σε όλες τις συσκευές.
Παρόμοιες με LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Every Friday and Sunday, Slate’s popular daily news podcast What Next brings you TBD, a clear-eyed look into the future. From fake news to fake meat, algorithms to augmented reality, Lizzie O’Leary is your guide to the tech industry and the world it’s creating for us to live in.
…
continue reading
Satguru Mata Sudiksha Ji Maharaj Discourses Podcast Channel
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Εφαρμογή podcast
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !



