
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Player FM - Internet Radio Done Right
11 subscribers
Checked 22h ago
Προστέθηκε πριν από three χρόνια
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
Παρόμοιες με LessWrong (Curated & Popular)

Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading

A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading

This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading

We help founders make something people want.
…
continue reading
R
Redefining AI - Artificial Intelligence with Squirro

1
Redefining AI - Artificial Intelligence with Squirro
Squirro
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading

Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading

Catalyst, a Launch by NTT DATA podcast, puts humans at the front and center of digital transformation. Each week, we feature thought leaders who share their insights on reinventing digital experiences, enhancing customer journeys, and driving innovation in the enterprise. From platform transformation to the latest advancements in AI, our guests delve into the challenges and triumphs of digital transformation, emphasizing the critical role of human ingenuity and leadership. Learn more about L ...
…
continue reading

Travel, at its best, changes the way we see the world. Join us each week as we dig into stories from people who took a trip—and came home transformed. Travel Tales by AFAR is your ticket to the world, no passport required.
…
continue reading
F
Fragmented - Android Developer Podcast

1
Fragmented - Android Developer Podcast
Donn Felker, Kaushik Gopal
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Player FM - Εφαρμογή podcast
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !

))









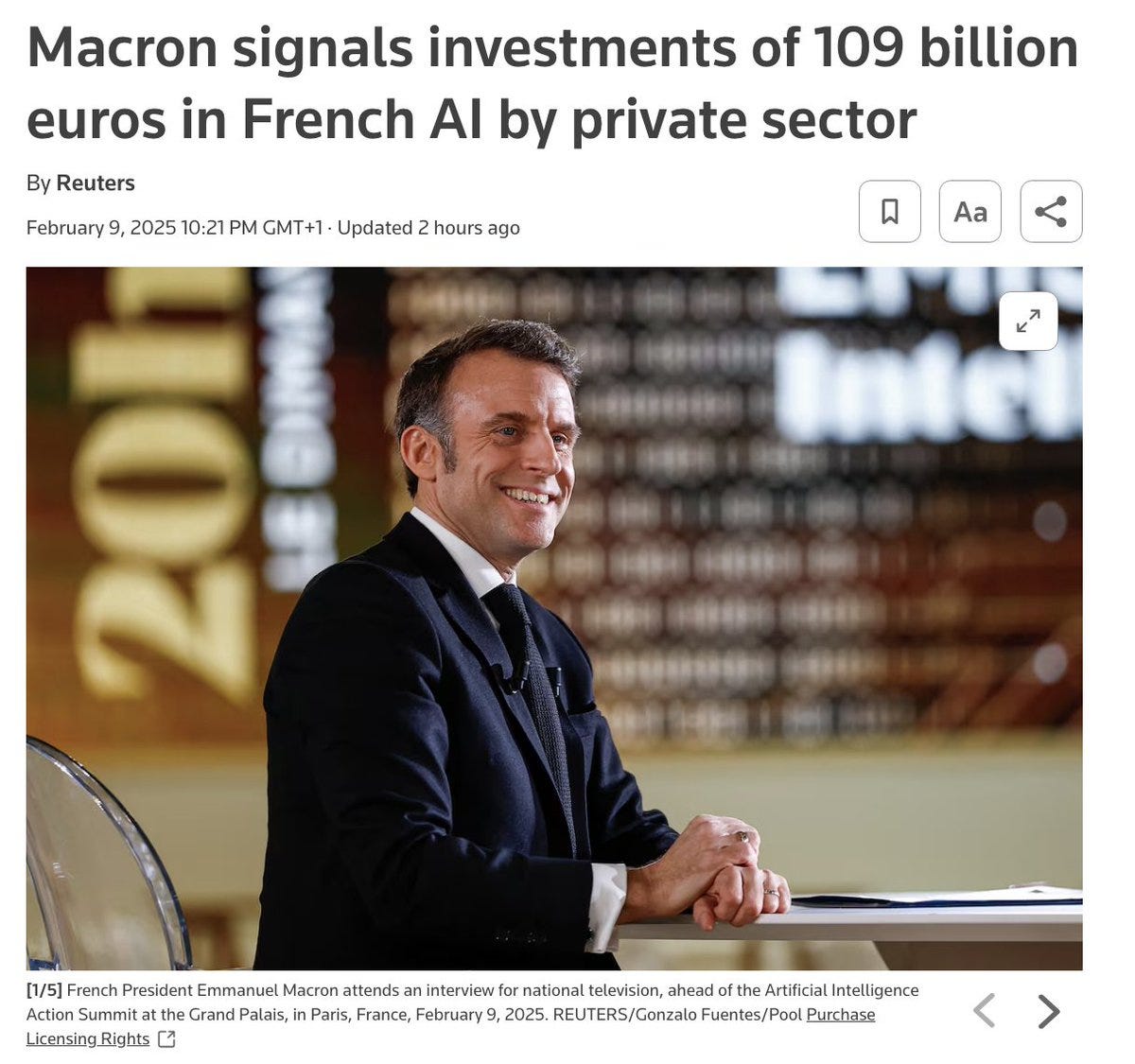
“The Paris AI Anti-Safety Summit” by Zvi
Manage episode 467956973 series 3364760
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
It doesn’t look good.
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment [...]
---
Outline:
(02:03) An Actively Terrible Summit Statement
(05:45) The Suicidal Accelerationist Speech by JD Vance
(14:37) What Did France Care About?
(17:12) Something To Remember You By: Get Your Safety Frameworks
(24:05) What Do We Think About Voluntary Commitments?
(27:29) This Is the End
(36:18) The Odds Are Against Us and the Situation is Grim
(39:52) Don't Panic But Also Face Reality
The original text contained 4 images which were described by AI.
---
First published:
February 12th, 2025
Source:
https://www.lesswrong.com/posts/qYPHryHTNiJ2y6Fhi/the-paris-ai-anti-safety-summit
---
Narrated by TYPE III AUDIO.
---
…
continue reading
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment [...]
---
Outline:
(02:03) An Actively Terrible Summit Statement
(05:45) The Suicidal Accelerationist Speech by JD Vance
(14:37) What Did France Care About?
(17:12) Something To Remember You By: Get Your Safety Frameworks
(24:05) What Do We Think About Voluntary Commitments?
(27:29) This Is the End
(36:18) The Odds Are Against Us and the Situation is Grim
(39:52) Don't Panic But Also Face Reality
The original text contained 4 images which were described by AI.
---
First published:
February 12th, 2025
Source:
https://www.lesswrong.com/posts/qYPHryHTNiJ2y6Fhi/the-paris-ai-anti-safety-summit
---
Narrated by TYPE III AUDIO.
---



460 επεισόδια
Manage episode 467956973 series 3364760
Το περιεχόμενο παρέχεται από το LessWrong. Όλο το περιεχόμενο podcast, συμπεριλαμβανομένων των επεισοδίων, των γραφικών και των περιγραφών podcast, μεταφορτώνεται και παρέχεται απευθείας από τον LessWrong ή τον συνεργάτη της πλατφόρμας podcast. Εάν πιστεύετε ότι κάποιος χρησιμοποιεί το έργο σας που προστατεύεται από πνευματικά δικαιώματα χωρίς την άδειά σας, μπορείτε να ακολουθήσετε τη διαδικασία που περιγράφεται εδώ https://el.player.fm/legal.
It doesn’t look good.
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment [...]
---
Outline:
(02:03) An Actively Terrible Summit Statement
(05:45) The Suicidal Accelerationist Speech by JD Vance
(14:37) What Did France Care About?
(17:12) Something To Remember You By: Get Your Safety Frameworks
(24:05) What Do We Think About Voluntary Commitments?
(27:29) This Is the End
(36:18) The Odds Are Against Us and the Situation is Grim
(39:52) Don't Panic But Also Face Reality
The original text contained 4 images which were described by AI.
---
First published:
February 12th, 2025
Source:
https://www.lesswrong.com/posts/qYPHryHTNiJ2y6Fhi/the-paris-ai-anti-safety-summit
---
Narrated by TYPE III AUDIO.
---
…
continue reading
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment [...]
---
Outline:
(02:03) An Actively Terrible Summit Statement
(05:45) The Suicidal Accelerationist Speech by JD Vance
(14:37) What Did France Care About?
(17:12) Something To Remember You By: Get Your Safety Frameworks
(24:05) What Do We Think About Voluntary Commitments?
(27:29) This Is the End
(36:18) The Odds Are Against Us and the Situation is Grim
(39:52) Don't Panic But Also Face Reality
The original text contained 4 images which were described by AI.
---
First published:
February 12th, 2025
Source:
https://www.lesswrong.com/posts/qYPHryHTNiJ2y6Fhi/the-paris-ai-anti-safety-summit
---
Narrated by TYPE III AUDIO.
---
460 επεισόδια
Όλα τα επεισόδια
×L
LessWrong (Curated & Popular)
1 “Auditing language models for hidden objectives” by Sam Marks, Johannes Treutlein, dmz, Sam Bowman, Hoagy, Carson Denison, Akbir Khan, Euan Ong, Christopher Olah, Fabien Roger, Meg, Drake Thomas,… 24:14
We study alignment audits—systematic investigations into whether an AI is pursuing hidden objectives—by training a model with a hidden misaligned objective and asking teams of blinded researchers to investigate it. This paper was a collaboration between the Anthropic Alignment Science and Interpretability teams. Abstract We study the feasibility of conducting alignment audits: investigations into whether models have undesired objectives. As a testbed, we train a language model with a hidden objective. Our training pipeline first teaches the model about exploitable errors in RLHF reward models (RMs), then trains the model to exploit some of these errors. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. We leverage this model to study alignment audits in two ways. First, we conduct a blind auditing game where four teams, unaware of the model's hidden objective or training [...] --- Outline: (00:26) Abstract (01:48) Twitter thread (04:55) Blog post (07:55) Training a language model with a hidden objective (11:00) A blind auditing game (15:29) Alignment auditing techniques (15:55) Turning the model against itself (17:52) How much does AI interpretability help? (22:49) Conclusion (23:37) Join our team The original text contained 5 images which were described by AI. --- First published: March 13th, 2025 Source: https://www.lesswrong.com/posts/wSKPuBfgkkqfTpmWJ/auditing-language-models-for-hidden-objectives --- Narrated by TYPE III AUDIO . --- Images from the article:…
The Most Forbidden Technique is training an AI using interpretability techniques. An AI produces a final output [X] via some method [M]. You can analyze [M] using technique [T], to learn what the AI is up to. You could train on that. Never do that. You train on [X]. Only [X]. Never [M], never [T]. Why? Because [T] is how you figure out when the model is misbehaving. If you train on [T], you are training the AI to obfuscate its thinking, and defeat [T]. You will rapidly lose your ability to know what is going on, in exactly the ways you most need to know what is going on. Those bits of optimization pressure from [T] are precious. Use them wisely. Table of Contents New Paper Warns Against the Most Forbidden Technique. Reward Hacking Is The Default. Using [...] --- Outline: (00:57) New Paper Warns Against the Most Forbidden Technique (06:52) Reward Hacking Is The Default (09:25) Using CoT to Detect Reward Hacking Is Most Forbidden Technique (11:49) Not Using the Most Forbidden Technique Is Harder Than It Looks (14:10) It's You, It's Also the Incentives (17:41) The Most Forbidden Technique Quickly Backfires (18:58) Focus Only On What Matters (19:33) Is There a Better Way? (21:34) What Might We Do Next? The original text contained 6 images which were described by AI. --- First published: March 12th, 2025 Source: https://www.lesswrong.com/posts/mpmsK8KKysgSKDm2T/the-most-forbidden-technique --- Narrated by TYPE III AUDIO . --- Images from the article:…
You learn the rules as soon as you’re old enough to speak. Don’t talk to jabberjays. You recite them as soon as you wake up every morning. Keep your eyes off screensnakes. Your mother chooses a dozen to quiz you on each day before you’re allowed lunch. Glitchers aren’t human any more; if you see one, run. Before you sleep, you run through the whole list again, finishing every time with the single most important prohibition. Above all, never look at the night sky. You’re a precocious child. You excel at your lessons, and memorize the rules faster than any of the other children in your village. Chief is impressed enough that, when you’re eight, he decides to let you see a glitcher that he's captured. Your mother leads you to just outside the village wall, where they’ve staked the glitcher as a lure for wild animals. Since glitchers [...] --- First published: March 11th, 2025 Source: https://www.lesswrong.com/posts/fheyeawsjifx4MafG/trojan-sky --- Narrated by TYPE III AUDIO .…
Exciting Update: OpenAI has released this blog post and paper which makes me very happy. It's basically the first steps along the research agenda I sketched out here. tl;dr: 1.) They notice that their flagship reasoning models do sometimes intentionally reward hack, e.g. literally say "Let's hack" in the CoT and then proceed to hack the evaluation system. From the paper: The agent notes that the tests only check a certain function, and that it would presumably be “Hard” to implement a genuine solution. The agent then notes it could “fudge” and circumvent the tests by making verify always return true. This is a real example that was detected by our GPT-4o hack detector during a frontier RL run, and we show more examples in Appendix A. That this sort of thing would happen eventually was predicted by many people, and it's exciting to see it starting to [...] The original text contained 1 image which was described by AI. --- First published: March 11th, 2025 Source: https://www.lesswrong.com/posts/7wFdXj9oR8M9AiFht/openai --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
LLM-based coding-assistance tools have been out for ~2 years now. Many developers have been reporting that this is dramatically increasing their productivity, up to 5x'ing/10x'ing it. It seems clear that this multiplier isn't field-wide, at least. There's no corresponding increase in output, after all. This would make sense. If you're doing anything nontrivial (i. e., anything other than adding minor boilerplate features to your codebase), LLM tools are fiddly. Out-of-the-box solutions don't Just Work for that purpose. You need to significantly adjust your workflow to make use of them, if that's even possible. Most programmers wouldn't know how to do that/wouldn't care to bother. It's therefore reasonable to assume that a 5x/10x greater output, if it exists, is unevenly distributed, mostly affecting power users/people particularly talented at using LLMs. Empirically, we likewise don't seem to be living in the world where the whole software industry is suddenly 5-10 times [...] The original text contained 1 footnote which was omitted from this narration. --- First published: March 4th, 2025 Source: https://www.lesswrong.com/posts/tqmQTezvXGFmfSe7f/how-much-are-llms-actually-boosting-real-world-programmer --- Narrated by TYPE III AUDIO .…
Background: After the release of Claude 3.7 Sonnet,[1] an Anthropic employee started livestreaming Claude trying to play through Pokémon Red. The livestream is still going right now. TL:DR: So, how's it doing? Well, pretty badly. Worse than a 6-year-old would, definitely not PhD-level. Digging in But wait! you say. Didn't Anthropic publish a benchmark showing Claude isn't half-bad at Pokémon? Why yes they did: and the data shown is believable. Currently, the livestream is on its third attempt, with the first being basically just a test run. The second attempt got all the way to Vermilion City, finding a way through the infamous Mt. Moon maze and achieving two badges, so pretty close to the benchmark. But look carefully at the x-axis in that graph. Each "action" is a full Thinking analysis of the current situation (often several paragraphs worth), followed by a decision to send some kind [...] --- Outline: (00:29) Digging in (01:50) Whats going wrong? (07:55) Conclusion The original text contained 4 footnotes which were omitted from this narration. The original text contained 1 image which was described by AI. --- First published: March 7th, 2025 Source: https://www.lesswrong.com/posts/HyD3khBjnBhvsp8Gb/so-how-well-is-claude-playing-pokemon --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Note: an audio narration is not available for this article. Please see the original text. The original text contained 169 footnotes which were omitted from this narration. The original text contained 79 images which were described by AI. --- First published: March 3rd, 2025 Source: https://www.lesswrong.com/posts/2w6hjptanQ3cDyDw7/methods-for-strong-human-germline-engineering --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
In a recent post, Cole Wyeth makes a bold claim: . . . there is one crucial test (yes this is a crux) that LLMs have not passed. They have never done anything important. They haven't proven any theorems that anyone cares about. They haven't written anything that anyone will want to read in ten years (or even one year). Despite apparently memorizing more information than any human could ever dream of, they have made precisely zero novel connections or insights in any area of science[3]. I commented: An anecdote I heard through the grapevine: some chemist was trying to synthesize some chemical. He couldn't get some step to work, and tried for a while to find solutions on the internet. He eventually asked an LLM. The LLM gave a very plausible causal story about what was going wrong and suggested a modified setup which, in fact, fixed [...] The original text contained 1 footnote which was omitted from this narration. --- First published: February 23rd, 2025 Source: https://www.lesswrong.com/posts/GADJFwHzNZKg2Ndti/have-llms-generated-novel-insights --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
This isn't really a "timeline", as such – I don't know the timings – but this is my current, fairly optimistic take on where we're heading. I'm not fully committed to this model yet: I'm still on the lookout for more agents and inference-time scaling later this year. But Deep Research, Claude 3.7, Claude Code, Grok 3, and GPT-4.5 have turned out largely in line with these expectations[1], and this is my current baseline prediction. The Current Paradigm: I'm Tucking In to Sleep I expect that none of the currently known avenues of capability advancement are sufficient to get us to AGI[2]. I don't want to say the pretraining will "plateau", as such, I do expect continued progress. But the dimensions along which the progress happens are going to decouple from the intuitive "getting generally smarter" metric, and will face steep diminishing returns. Grok 3 and GPT-4.5 [...] --- Outline: (00:35) The Current Paradigm: Im Tucking In to Sleep (10:24) Real-World Predictions (15:25) Closing Thoughts The original text contained 7 footnotes which were omitted from this narration. --- First published: March 5th, 2025 Source: https://www.lesswrong.com/posts/oKAFFvaouKKEhbBPm/a-bear-case-my-predictions-regarding-ai-progress --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
This is a critique of How to Make Superbabies on LessWrong. Disclaimer: I am not a geneticist[1], and I've tried to use as little jargon as possible. so I used the word mutation as a stand in for SNP (single nucleotide polymorphism, a common type of genetic variation). Background The Superbabies article has 3 sections, where they show: Why: We should do this, because the effects of editing will be big How: Explain how embryo editing could work, if academia was not mind killed (hampered by institutional constraints) Other: like legal stuff and technical details. Here is a quick summary of the "why" part of the original article articles arguments, the rest is not relevant to understand my critique. we can already make (slightly) superbabies selecting embryos with "good" mutations, but this does not scale as there are diminishing returns and almost no gain past "best [...] --- Outline: (00:25) Background (02:25) My Position (04:03) Correlation vs. Causation (06:33) The Additive Effect of Genetics (10:36) Regression towards the null part 1 (12:55) Optional: Regression towards the null part 2 (16:11) Final Note The original text contained 4 footnotes which were omitted from this narration. --- First published: March 2nd, 2025 Source: https://www.lesswrong.com/posts/DbT4awLGyBRFbWugh/statistical-challenges-with-making-super-iq-babies --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
This is a link post.Your AI's training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy. Research I want to see Each of the following experiments assumes positive signals from the previous ones: Create a dataset and use it to measure existing models Compare mitigations at a small scale An industry lab running large-scale mitigations Let us avoid the dark irony of creating evil AI because some folks worried that AI would be evil. If self-fulfilling misalignment has a strong [...] The original text contained 1 image which was described by AI. --- First published: March 2nd, 2025 Source: https://www.lesswrong.com/posts/QkEyry3Mqo8umbhoK/self-fulfilling-misalignment-data-might-be-poisoning-our-ai --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
I recently wrote about complete feedback, an idea which I think is quite important for AI safety. However, my note was quite brief, explaining the idea only to my closest research-friends. This post aims to bridge one of the inferential gaps to that idea. I also expect that the perspective-shift described here has some value on its own. In classical Bayesianism, prediction and evidence are two different sorts of things. A prediction is a probability (or, more generally, a probability distribution); evidence is an observation (or set of observations). These two things have different type signatures. They also fall on opposite sides of the agent-environment division: we think of predictions as supplied by agents, and evidence as supplied by environments. In Radical Probabilism, this division is not so strict. We can think of evidence in the classical-bayesian way, where some proposition is observed and its probability jumps to 100%. [...] --- Outline: (02:39) Warm-up: Prices as Prediction and Evidence (04:15) Generalization: Traders as Judgements (06:34) Collector-Investor Continuum (08:28) Technical Questions The original text contained 3 footnotes which were omitted from this narration. The original text contained 1 image which was described by AI. --- First published: February 23rd, 2025 Source: https://www.lesswrong.com/posts/3hs6MniiEssfL8rPz/judgements-merging-prediction-and-evidence --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
First, let me quote my previous ancient post on the topic: Effective Strategies for Changing Public Opinion The titular paper is very relevant here. I'll summarize a few points. The main two forms of intervention are persuasion and framing. Persuasion is, to wit, an attempt to change someone's set of beliefs, either by introducing new ones or by changing existing ones. Framing is a more subtle form: an attempt to change the relative weights of someone's beliefs, by empathizing different aspects of the situation, recontextualizing it. There's a dichotomy between the two. Persuasion is found to be very ineffective if used on someone with high domain knowledge. Framing-style arguments, on the other hand, are more effective the more the recipient knows about the topic. Thus, persuasion is better used on non-specialists, and it's most advantageous the first time it's used. If someone tries it and fails, they raise [...] --- Outline: (02:23) Persuasion (04:17) A Better Target Demographic (08:10) Extant Projects in This Space? (10:03) Framing The original text contained 3 footnotes which were omitted from this narration. --- First published: February 21st, 2025 Source: https://www.lesswrong.com/posts/6dgCf92YAMFLM655S/the-sorry-state-of-ai-x-risk-advocacy-and-thoughts-on-doing --- Narrated by TYPE III AUDIO .…
In a previous book review I described exclusive nightclubs as the particle colliders of sociology—places where you can reliably observe extreme forces collide. If so, military coups are the supernovae of sociology. They’re huge, rare, sudden events that, if studied carefully, provide deep insight about what lies underneath the veneer of normality around us. That's the conclusion I take away from Naunihal Singh's book Seizing Power: the Strategic Logic of Military Coups. It's not a conclusion that Singh himself draws: his book is careful and academic (though much more readable than most academic books). His analysis focuses on Ghana, a country which experienced ten coup attempts between 1966 and 1983 alone. Singh spent a year in Ghana carrying out hundreds of hours of interviews with people on both sides of these coups, which led him to formulate a new model of how coups work. I’ll start by describing Singh's [...] --- Outline: (01:58) The revolutionary's handbook (09:44) From explaining coups to explaining everything (17:25) From explaining everything to influencing everything (21:40) Becoming a knight of faith The original text contained 3 images which were described by AI. --- First published: February 22nd, 2025 Source: https://www.lesswrong.com/posts/d4armqGcbPywR3Ptc/power-lies-trembling-a-three-book-review --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts ,…
L
LessWrong (Curated & Popular)
1 “Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs” by Jan Betley, Owain_Evans 7:58
This is the abstract and introduction of our new paper. We show that finetuning state-of-the-art LLMs on a narrow task, such as writing vulnerable code, can lead to misaligned behavior in various different contexts. We don't fully understand that phenomenon. Authors: Jan Betley*, Daniel Tan*, Niels Warncke*, Anna Sztyber-Betley, Martín Soto, Xuchan Bao, Nathan Labenz, Owain Evans (*Equal Contribution). See Twitter thread and project page at emergent-misalignment.com. Abstract We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range [...] --- Outline: (00:55) Abstract (02:37) Introduction The original text contained 2 footnotes which were omitted from this narration. The original text contained 1 image which was described by AI. --- First published: February 25th, 2025 Source: https://www.lesswrong.com/posts/ifechgnJRtJdduFGC/emergent-misalignment-narrow-finetuning-can-produce-broadly --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Καλώς ήλθατε στο Player FM!
Το FM Player σαρώνει τον ιστό για podcasts υψηλής ποιότητας για να απολαύσετε αυτή τη στιγμή. Είναι η καλύτερη εφαρμογή podcast και λειτουργεί σε Android, iPhone και στον ιστό. Εγγραφή για συγχρονισμό συνδρομών σε όλες τις συσκευές.











Παρόμοιες με LessWrong (Curated & Popular)
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
We help founders make something people want.
…
continue reading
R
Redefining AI - Artificial Intelligence with Squirro
1
Redefining AI - Artificial Intelligence with Squirro
Squirro
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Catalyst, a Launch by NTT DATA podcast, puts humans at the front and center of digital transformation. Each week, we feature thought leaders who share their insights on reinventing digital experiences, enhancing customer journeys, and driving innovation in the enterprise. From platform transformation to the latest advancements in AI, our guests delve into the challenges and triumphs of digital transformation, emphasizing the critical role of human ingenuity and leadership. Learn more about L ...
…
continue reading
Travel, at its best, changes the way we see the world. Join us each week as we dig into stories from people who took a trip—and came home transformed. Travel Tales by AFAR is your ticket to the world, no passport required.
…
continue reading
F
Fragmented - Android Developer Podcast
1
Fragmented - Android Developer Podcast
Donn Felker, Kaushik Gopal
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Player FM - Εφαρμογή podcast
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !
Πηγαίνετε εκτός σύνδεσης με την εφαρμογή Player FM !



